分散バージョン管理入門 (イラスト入り)
Kalid Azad、 2007 年 10 月 15 日、 原文 (original post)")
![]()
従来のバージョン管理は、ファイルをバックアップ・追跡・同期するのに役立った。 分散バージョン管理を使うと、変更内容を共有するのが楽になる。 さぁ、両方の長所を活かすんだ。簡単なマージと一括管理されたリリースを。
分散だって? これまでのバージョン管理で何がまずいの?
別に…。 さっ、気を取り戻したければ、 バージョン管理へのビジュアルガイド(英語) を読んで。 もちろん、「古くさい」システムを使っているとバカにする人もいるだろう。 けれど、私はそれで全然かまわないと思う。 どんなバージョン管理システム(VCS)を使うにしても、プロジェクトにとっては前向きな一歩なんだから。
集中型バージョン管理システムは 1970 年頃に現れた。 その頃プログラマーには、シンクライアントと “big iron” と称されたメインフレームがあった。 (当時で贅沢な 8 ビットが 1 バイト のマシンが好きになれないなんてことがあるだろうか?)
集中型は単純で、まず最初に考案されたのがこれだ。 みんなが一ヶ所にチェックイン・チェックアウトする。 これは、本の上に落書きできるようになった図書館みたいなもんだ。
このモデルでは、 バックアップ・取り消し・同期については上手くいくけど、 複数人で変更点をマージ・ブランチするには向いていない。 プロジェクトが大きくなるにつれて、機能をブロックに分割し、 隔離した状態で開発やテストを行い、変更は緩やかにメインラインへマージしたくなるだろう。 けれど、ブランチが厄介なもんだから、現実には新機能は巨大なチェックインになってしまう。 これでは変更内容が間違っていたと分かっても、問題に対処し解決するのは困難だ。
もちろん、集中型システムでも以前からマージは「可能」だ。けれど、簡単ではない。 自分でマージを追跡して、同じ変更を繰り返してしまわないようにする必要があるんだ。 分散型システムはブランチとマージを楽にしてくれる。分散型はそれに頼っているからね。
ちょっと図をいくつか
他のチュートリアルでは、具体的なテキストコマンドをたっぷり用意しているけど、ここではイメージを話そう。 少し気分を戻して、開発者は典型的な VCS を使っていて、中央リポジトリへアクセスするとしよう。
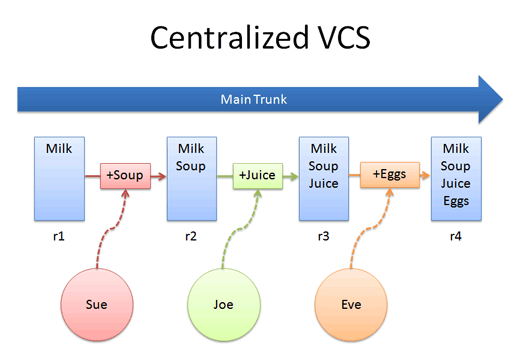
全員が同期を取ってからメイントランクへチェックインする。 Sue は soup を、 Joe は juice を、 Eve は eggs を追加する。
Sue の変更は、メインへ入るまで他の人が目にすることはない。 まぁ、理論上 Sue は別ブランチを作って、他の人に変更をテストしてもらうことができなくはないけれど、 従来の VCS でそうするのは面倒だ。
分散バージョン管理システム (DVCS)
分散モデルでは、開発者には自分専用のリポジトリがある。 Sue の変更は彼女のローカルリポジトリに存在し、 必要に応じて Joe や Eve と共有できる。
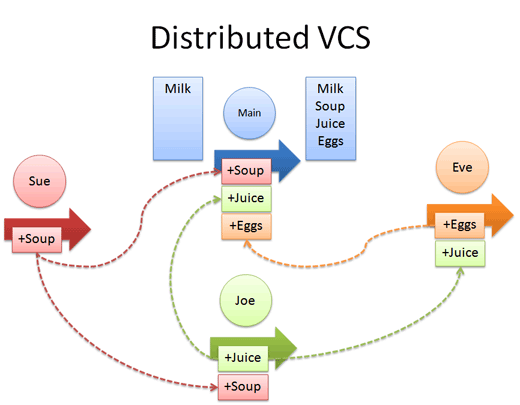
けれど、リングリーダー無しでは大混乱してしまわないかな? いいや、 必要なら全員が共通リポジトリへ変更を送りつける(push)ようにすればいい。 上の中央リポジトリのようにね。 このフランケンシュタイン・リポジトリには Sue と Joe と Eve の変更が入っている。
分散バージョン管理は、もっと別の名前のほうが良かったと思う。 例えば、「独立」、「連合」、「ピアツーピア(P2P)」みたいな。 「分散」という言葉からは分散コンピューティングを連想してしまうし、 そこでは作業はグリッドマシン間で分割される。 (SETI@home の信号探索や たんぱく質の折り畳み のように。)
DVCS は Seti@home のようなものではない。各ノードは完全に独立しており、 共有するかしないかは自由だ。(Seti では結果を送り返さなくちゃならない。)
主な概念を 5 分で
基本をここで。もし興味を持ったなら、パッチ理論についての 本(英語) がある。
コア概念
- 集中型バージョン管理は、 ファイルの同期・追跡・バックアップ を念頭に置いている。
- 分散バージョン管理は、 変更の共有 を重視している。 変更にはそれぞれ GUID や一意の識別子 がつく。
- 変更の 記録・ダウンロード・適用 は、全て別のステップ。 (集中型システムでは、これらがいっぺんに起こる。)
- 分散型システムでは、レイアウトは強制されない。 「集中管理」された場所を作ることもできるし、各々を対等にしておいても構わない。
新しい用語
- push: 変更を他のリポジトリへ送りつける (許可が必要な場合あり)
- pull: 変更をリポジトリから取り込む
主なメリット
- みんな自分のサンドボックスを持っている。 変更を加えたり元に戻したり、 すべて自分のローカルマシンで行える。もう、巨大なチェックインなどあり得ない。 途中経過が自分のリポジトリにあるんだから。
- オフラインで動く。 変更を共有する時だけオンラインになればよい。 つまり、「サーバー」がダウンしてるとか飛行機に乗っているとか関係なしで、 ローカルマシン上で自由にチェックインや取り消しができるってことだ。
- 速い。 差分(diff)・コミット・取り消しは全てローカルで片付く。 1年前の古いリビジョンであっても、当てにならないネットワークやサーバー問い合わせは必要ない。
- 変更を上手く扱える。 分散バージョン管理システムは、変更の共有を中心に据えている。 変更には全て GUID が振られており、追跡しやすくなっている。
- ブランチとマージが簡単。 開発者がみんな「自分のブランチ」を持っているから、 変更を共有することは、逆方向に統合してるように思えるだろう。けれど、 GUID のおかげで、 変更の組み合わせと重複回避は自動的になされる。
- 管理が楽。 分散バージョン管理システムは、動かすのが簡単だ。 「24 時間稼動」のサーバーソフトをインストールする必要がない。 同様に、 DVCS では新しいユーザーの「追加」も必須ではない。 pull 元の URL を決めるだけでいい。 つまり、大きなプロジェクトでの政治的な頭痛の種から逃れられるということだ。
主なデメリット
- 依然バックアップは必要。 他のマシンに自分の変更があるから、それが「バックアップ」だと言う人もいるけれど、 私はそうは思わない。そのマシンがあなたの変更を受け入れていなかったら? そのマシンがオフラインになってから、あなたが別の変更を行ったら? DVCS であっても、 「念のために」変更を push しておくマシンは必要だ。 (Subversion では、大抵メインリポジトリを保存しておく別マシンを用意するよね。 DVCS でも同じようにして。)
- 本当のところ「最新バージョン」は無い。 中央リポジトリがなければ、 最新バージョンが Sue のものか、あるいは Joe か、 Eve か、すぐには分からない。 なお、中央リポジトリがあれば、最新の「安定版」も明確になる。
- 本当の意味でリビジョン番号は無い。 リポジトリにはそれぞれ、変更に応じた固有のリビジョン番号がある。 つまり、リビジョン番号の代わりに、変更番号を引用するということだ。 すみません、 fa33e7b の変更はありますか? (ID がひどい GUID だってことを忘れないで。) 幸い、有意義な名前でリリースにタグづけすることができる。
Mercurial クイックスタート
Mercurial は高速かつ分かりやすい DVCS だ。ニックネームは hg で、これは水銀(Mercury)の元素記号から取られた。
cd project
hg init (リポジトリをここに作成)
hg add list.txt (ファイルを追跡開始)
hg commit -m "Added file" (ファイルをローカルリポジトリへチェックイン)
hg log (履歴を見る ... GUID が振られている)
チェンジセット: 0:55bbcb7a4c24
ユーザ: Kalid@kazad-laptop
日付: Sun Oct 14 21:36:18 2007 -0400
要約: Added file
[ファイルを編集]
hg revert list.txt (直前のバージョンへ戻す)
hg tag v1.0 (このバージョンをタグづけ)
[ファイルを編集]
hg update -C v1.0 (以前のタグづけされたバージョンへ「更新(update)」 ... -C はローカルコピーを強制的に上書きする)
Mercurial がディレクトリを初期化すると、このようになる。
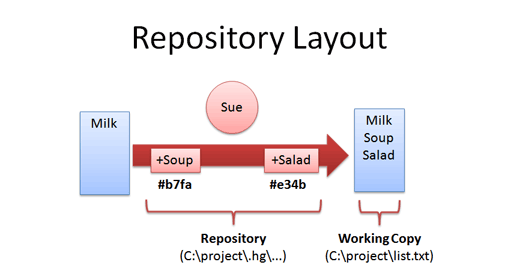
ここにあるのは、
- 作業コピー。 あなたが今編集中のファイル。
- リポジトリ。 パッチとメタデータ(コメント、 GUID 、日付など)が全部入っているディレクトリ (Mercurial では .hg)。 中央サーバーが無いので、データはいつも手元にあるわけだ。
この記事の分散リポジトリ例では、 Sue、 Joe、 Eve にそれぞれ自分のリポジトリがあって、 その中に独自のリビジョン履歴がある。
更新とマージを理解する
DVCS を学ぶ時に、いくつか勘違いしそうになったことがある。 まず、更新が数ステップを経るということ。
- 変更をリポジトリへ取り込み (push または pull)
- 変更をファイルへ適用 (update または merge)
- 新しいバージョンを保存 (commit)
次に、変更に応じて、 更新(update)とマージ(merge)を使い分けること。
- 更新(update) は曖昧さが無い時に起こる。例えば、 あなただけが編集したファイルの変更を私が pull した場合。 重複した変更が無いから、 ファイルは最新リビジョンへ移動するだけだ。
- マージ(merge) は変更がぶつかった時に必要だ。 2 人がファイルを編集したら、最終的に 2 つの「ブランチ」(つまり、別々の世界)ができる。 一方の世界には私の変更が、他方にはあなたの変更がある。この場合、 (恐らく) 変更を 1 つの世界へマージしたいだろう。
DVCS でいとも簡単にブランチが現れマージされるということを、 私はまだはっきり理解できていない。
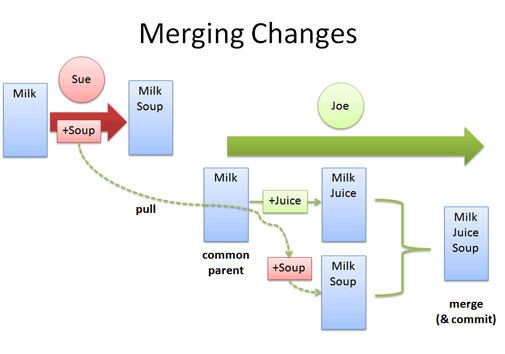
このケースでは、 (+Soup) と (+Juice) が共通の親(「Milk」だけを含むリスト) に対する変更であるため、マージが必要だ。 Joe がファイルをマージすると、 Sue はいつもの「pull と update」を実行するだけで、 Joe から連結されたファイルを取得できる。 彼女が自分の手で再度マージする必要はない。
Mercurial ではこのようにする。
hg incoming ../another-dir (pull 待ちの変更をチェック)
hg pull ../another-dir (変更をダウンロード)
hg update (変更を実際に適用...)
hg merge (... または、必要に応じてマージ)
hg commit (マージしたファイルをチェックイン ... ブランチを結合)
そう、「pull-merge-commit」サイクルは長い。運良く、 Mercurial には一連のコマンドをひとつにしたショートカットがある。 これは複雑そうに見えるけれど、 Subversion でマージを手作業で扱うよりはずっと簡単だ。
マージはたいてい自動だ。 衝突が見つかっても、大体はすぐに解決される。 Mercurial はすべての変更について親子関係を追跡しているんだ (さっきのマージされたリスト<訳注: 「Milk Juice Soup」のこと>には親が 2 つある)。 「ヘッド」 — つまり各ブランチの最新の変更についても同様だ。マージ前には 2 つヘッドがあり、マージ後ひとつになる。
分散型プロジェクトをまとめる
分散型プロジェクトをまとめ上げる方法をひとつ示そう。
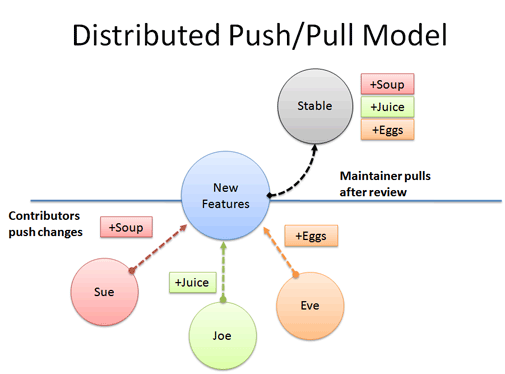
Sue と Joe と Eve は共通のブランチへチェックインする。 ちょっとした「仲間うちビルド(buddy build)」については、互いにパッチをやり取りする。 ねぇ、ちょっと、このパッチを試してくんない? 実験版ブランチへ push する前にちゃんと動くか確認しておきたいんだ。
その後、メンテナーは変更をレビューし、実験版ブランチから安定版(stable)ブランチへ pull するだろう。 このブランチに最新リリースがあるんだ。 分散 VCS は、変更を隔離しつつも、集中型システムのような「単一ソース」を提供するのに便利だ。 開発モデルは様々で、「pull のみ」(メンテナーが何を取り込むか決定する Linux 型開発モデル) から、「共用 push」(集中型システムのように振る舞う)まで多種多様だ。分散 VCS は、 プロジェクトの運用方法に柔軟性をもたらしてくれるんだ。
最後に実践と痛烈な酷評を
私は DVCS 初心者だけど、これまでのところ身につけたことに満足している。私は SVN を好きで使っているけど、 それでもマージの手軽さに出会うことは実に「楽しい」。 私の提案としては、 Subversion から始めて、チームでの協力作業の要点を理解した後、 分散モデルを試してみるのがよいだろう。適切にレイアウトすることで、 DVCS は集中型システムでできること全てをこなせるし、その上、手軽なマージの恩恵を受けられるんだ。
オンラインの資料
- Mercurial には 素晴らしい本 がある。 Windows 上では、 差分・マージソフト か TortoiseMerge (TortoiseSVN をインストールしている場合) が必要だろう。
- Darcs には詳細な wikibook がある (変更についての数学理論について触れられている)。
- Git は Linus Torvalds によって開発された。 DVCS についての 興味深いレクチャー をどうぞ。集中型システムについて激しく非難されるから、覚悟しておこう。 <訳注: 一部抜粋し日本語に訳した記事 がある。>
注目はココ:
- 「ブランチとマージをやったことあるのはどれくらい? それが楽しかった人はいるかい?」
- 「マージするには、前もって 1 週間計画を練って、それから丸 1 日を無駄にするんだ。」
- 「5、 10、 15 ぐらいブランチを持ってる人がいる。ひとつは実験用、もう一つは保守用、…だ。」
- 「CVS — コミットなんかしないよ。コミットせずに変更を続けるんだ。 巨大なテストスイートをパスするまでは絶対コミットなんてしない。一直線の変更を続けるんだ、 それが どうあっても 壊れないって知ってるから。」
さぁ、がんばって、宗教戦争に気をつけよう。どんな tip や提案でも、自由にどうぞ。
翻訳: 西原 佑哉 、 2010 年 2 月 7 日 、 原文 (original post)